
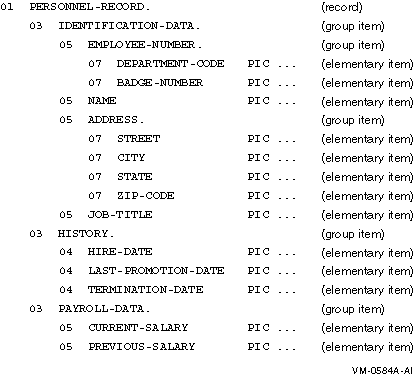
FD MASTER-FILE.
01 T1.
02 T1-ACCOUNT-NO PIC 9(6).
02 T1-TRAN-CODE PIC 99.
02 T1-NAME PIC X(13).
02 T1-BALANCE PIC 9(5)V99.
02 REC-TYPE PIC XX.
01 T2.
02 T2-ACCOUNT-NO PIC 9(6).
02 T2-ADDRESS.
03 T2-STREET PIC X(15).
03 T2-CITY PIC X(7).
02 REC-TYPE PIC XX.
01 RECORD-TYPE.
02 PIC X(28).
02 REC-TYPE PIC XX.
|
The three record description entries in Example 5-1, T1, T2, and
RECORD-TYPE, each define a fixed-length record of 30 characters. Once
the program reads a record, it can use the last two characters
(REC-TYPE) to determine which record description entry to use.
5.2 Physical Concepts of Data Storage
COBOL programs describe files and data in physical terms for storage on input-output media. The physical description of data includes the following information:
- The mapping and grouping of logical records within the structure of the file storage medium
- The unit used to transfer records to and from your program
- The size and storage format of an elementary data item
The size of a physical record and the way it is recorded depend on the hardware device involved in an input or output operation. For example, tape and disk media store physical records differently. On tape, a physical record is written between interrecord gaps. On disk, a physical record is written in multiple units of a fixed number of bytes, which is determined by the hardware and operating system involved.
On OpenVMS Alpha systems, the term used for a physical record differs according to file organization. A physical record in a sequential file is called a block. A physical record in a relative or indexed file is called a bucket. A block or bucket corresponds to the unit used by the I/O system software to transfer records from a file to your program (and vice versa). The number of records (in logical terms) actually transferred by an input-output operation depends on the following:
- The block size specified by the BLOCK CONTAINS clause (tape files only)
- The number of logical records contained in a physical record
The maximum physical record size depends on file organization and device. On OpenVMS Alpha systems, the maximum physical record sizes for sequential files on tape devices and for sequential, indexed, and relative files on disk are shown in terms of number of bytes in Table 5-1.
| Type of File | Magnetic Tape Devices | Disk |
|---|---|---|
| Sequential | 65,535 bytes | 65,024 bytes |
| Indexed | N/A | 32,234 bytes |
| Relative | N/A | 32,255 bytes <> |
A compile-time informational diagnostic appears if the physical record size exceeds 65,024 bytes for a sequential file. However, Compaq COBOL programs are device-independent. Therefore, a fatal run-time error can also occur if the file is assigned to disk when the program runs. |
5.2.1 Categories and Classes of Data
The size and storage format of an elementary data item depend upon what class and category of data it represents and how that data can be used. A data item's PICTURE clause determines its class and category. The item's PICTURE clause and USAGE clause, in combination, specify its size and storage format. See the Section 5.3.37 and Section 5.3.52 clauses for more information.
When an arithmetic or data-movement statement transfers data into an elementary item, the category of the item affects the way the data is positioned in storage. The COBOL Standard Alignment Rules (see Section 5.2.2) specify the relationship between category and positioning.
Depending on the symbols contained in its PICTURE clause, every elementary item belongs to one of the classes and categories of data items shown in Table 5-2. COMP-1, COMP-2, index data items, and index-names do not have PICTURE clauses; the format of these elementary items is specified by the compiler and they belong to the numeric category.
The class of a group item is treated as alphanumeric regardless of the class of elementary items subordinate to it. Therefore, your program statements should not specify a group item when a numeric item is expected or required.
| Level | Class | Category |
|---|---|---|
|
Alphabetic |
Alphabetic |
|
| Elementary | Numeric | Numeric |
|
Alphanumeric |
Numeric Edited
Alphanumeric Edited Alphanumeric |
|
|
Group |
Alphanumeric |
Alphabetic
Numeric Numeric Edited Alphanumeric Edited Alphanumeric |
5.2.2 COBOL Standard Alignment Rules
The COBOL Standard Alignment Rules specify how characters are positioned in an elementary data item. Positioning depends on the item's category:
- For a numeric receiving data item:
- The data is aligned by decimal point. It is moved to the receiving character positions with zero fill or truncation, if necessary.
- When an assumed decimal point is not explicitly specified, the data item is treated as if it had an assumed decimal point immediately after its rightmost character. It is then aligned by decimal point as described in the preceding list item.
- For a numeric edited receiving data item, the data is aligned by decimal point with zero fill or truncation, if necessary. Editing requirements can replace leading zeros with some other symbol.
- For receiving data items that are alphabetic, alphanumeric edited, or alphanumeric (without editing), the data is aligned at the leftmost character position in the data item, with space fill or truncation to the right, if necessary.
If the JUSTIFIED clause applies to the receiving item, the rules for the
JUSTIFIED clause override rule 3. See the Section 5.3.28 clause for more
information.
5.2.3 Additional Alignment Rules for Record Allocation
As stated in Section 5.2.2, the COBOL Standard Alignment Rules specify data positioning only within elementary data items. Compaq defines additional alignment rules that affect the positioning of:
- Records on the file media
- Group items within a record
- Elementary items within a group item
Compaq COBOL offers the option of allocating subordinate record items along performance-optimal boundaries through the use of the alignment compiler option or directives (or the SYNCHRONIZE clause on OpenVMS Alpha). If you select one of these options, subordinate data items will be aligned automatically along optimal boundaries for their data type. The compiler may have to skip one or more bytes before assigning a location to the next data item. These skipped bytes, called fill bytes, are spaces between one data item and the next. See the Compaq COBOL User Manual for information on using alignment compiler options and directives.
If you do not select one of these alignment options, the Compaq COBOL compiler will locate the data item at the next unassigned byte location.
The presence of fill bytes can make a record's structure different from what you might expect. In particular, if a record contains many items requiring alignment, its size can increase significantly. If, unaware of the fill bytes, you tried to move a group item containing fill bytes to a single data item, right-end truncation would occur. You would not have this problem, however, if you moved the record into another identically defined group item. The method the compiler uses to allocate storage ensures that identically described group items have the same structure, even when their subordinate items are aligned on their required boundaries.
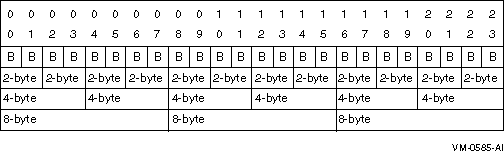
Figure 5-3 shows alignment boundaries for a record. The boundary is the leftmost location of the 1-, 2-, 4-, or 8-byte area. All boundaries are relative to the beginning of the record as byte number 0.
Figure 5-3 Record Alignment Boundaries
The Compaq COBOL compiler allocates storage for data items within records according to the rules of the major-minor equivalence technique. The major-minor equivalence technique ensures that identically defined group items have the same structure, even when their subordinate items are aligned. Therefore, group moves always produce predictable results. This technique is based on the following two rules:
- Location Equivalence---The leftmost location of a group item is the same as the leftmost location of its first subordinate item.
- Boundary Equivalence---The Compaq COBOL compiler aligns a group item on a boundary that is as large as the largest boundary for any aligned data item within its scope.
Location equivalence forces a group (major) item to the same storage location as its first subordinate (minor) item. This forced positioning occurs regardless of the boundary alignment of either the group or subordinate item.
See the Compaq COBOL User Manual chapter on aligning binary data for information on how location equivalence allocates storage.
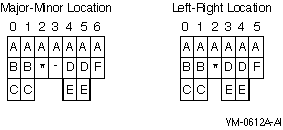
The following example results in the major-minor location format:
01 ITEM-A.
03 ITEM-B.
05 ITEM-C PIC 9(4) COMP SYNCHRONIZED.
03 FILLER PIC X.
03 ITEM-D.
05 ITEM-E PIC 9(4) COMP SYNCHRONIZED.
03 ITEM-F PIC X.
|
The following example (omitting SYNCHRONIZED) results in the left-right location format:
01 ITEM-A.
03 ITEM-B.
05 ITEM-C PIC 9(4) COMP.
03 FILLER PIC X.
03 ITEM-D.
05 ITEM-E PIC 9(4) COMP.
03 ITEM-F PIC X.
|
Table 5-3 compares the major-minor technique of storage allocation with the left-to-right technique that assigns locations to a group item before its subsidiary items. Note that major-minor storage allocation adds a fill byte before ITEM-D. This forces location equivalence with ITEM-E, which is explicitly aligned by the SYNCHRONIZED clause.
| Data Item | Major-Minor Location |
Left-Right Location |
|---|---|---|
| ITEM-A | 00 | 00 |
| ITEM-B | 00 | 00 |
| ITEM-C | 00 | 00 |
| FILLER | 02 | 02 |
| ITEM-D | 04 | 03 |
| ITEM-E | 04 | 03 |
| ITEM-F | 06 | 05 |
The following diagram also shows the storage allocation for the record ITEM-A in Table 5-3 using both techniques. A hyphen (-) represents fill bytes caused by explicit alignment; an asterisk (*) represents the FILLER data item.
Regardless of the record allocation technique, an elementary move always produces the expected result. For example:
MOVE ITEM-C TO ITEM-E |
A group move may produce an unexpected result, as in the following two situations:
- If ITEM-A of the major-minor location format is moved to ITEM-A of the left-right location format, the fill byte of the major-minor location format overlays the first byte of ITEM-E in the left-right location format; then the first byte of ITEM-E in the major-minor location format overlays the second byte of ITEM-E in the left-right location format, and the second byte of ITEM-E in the major-minor location format overlays ITEM-F in the left-right location format. Finally, ITEM-F in the major-minor location format is truncated.
- A different set of unexpected results occurs if a group move is done in the reverse direction. If ITEM-A of the left-right location format is moved to ITEM-A of the major-minor location format, the first byte of ITEM-D of the left-right location format is moved to the fill byte of the major-minor location format. Then the second byte of ITEM-E in the left-right location format is moved to the first byte of ITEM-E in the major-minor location format, and ITEM-F of the left-right location format is moved to the second byte of ITEM-E in the major-minor location format. Finally, ITEM-F is filled with a space because of the padding rule.
Boundary equivalence forces a group item to a boundary determined by the alignment of its subordinate items.
Within a record, a group item aligns on a boundary as large as the forced alignment boundary of any data item that:
- Is subordinate to the group
- Redefines the group
- Is subordinate to a data item that redefines the group
Refer to the Compaq COBOL User Manual chapter on alignment for more information about boundary equivalence.
Figure 5-4 shows how the compiler determines the boundary where each item begins when you specify the no-alignment compiler option.
Figure 5-4 Effect of Boundary and Location Equivalence Rules on Sample Record
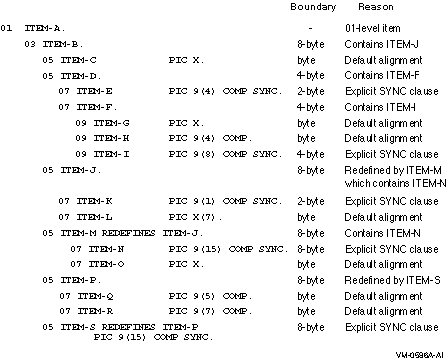
Figure 5-5 graphically represents Figure 5-4. It shows the result of location and boundary equivalence applied to the description of record ITEM-A. A hyphen (-) indicates fill bytes.
Figure 5-5 Storage Allocation for Sample Record
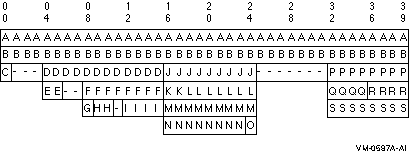
Note the location of ITEM-D. Location equivalence requires only that it have the same location as ITEM-E, its first subordinate item. ITEM-E requires only 2-byte boundary alignment. However, another of ITEM-D's subordinate items, ITEM-F, contains ITEM-I, which must be aligned on a 4-byte boundary. Therefore, boundary equivalence forces ITEM-D to a 4-byte boundary as well, causing two fill bytes between ITEM-E and ITEM-F.
This example shows how boundary equivalence helps make group moves predictable:
01 ITEM-A.
03 ITEM-B.
05 ITEM-C PIC X.
05 ITEM-D PIC 9(8) COMP SYNC.
03 ITEM-E PIC X.
03 ITEM-F.
05 ITEM-G PIC X.
05 ITEM-H PIC 9(8) COMP SYNC.
03 ITEM-I PIC XX.
|
The descriptions of ITEM-B and ITEM-F are equivalent. Therefore, you would not expect the following sentence to change the values of ITEM-C and ITEM-D:
MOVE ITEM-B TO ITEM-F MOVE ITEM-F TO ITEM-B. |
Figure 5-6 shows how storage for the record would be allocated without and with boundary equivalence. A hyphen (-) indicates fill bytes caused by the SYNCHRONIZED clause. A plus sign (+) represents fill bytes resulting from boundary equivalence.
Figure 5-6 Storage Allocation Without and With Boundary Equivalence
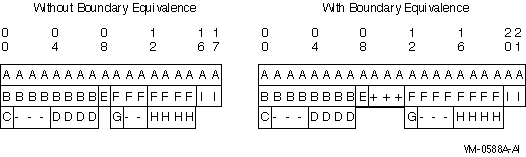
Without boundary equivalence, ITEM-B occupies 8 bytes, and ITEM-F occupies 7 bytes. Moving the contents of ITEM-B to ITEM-F truncates the last byte of ITEM-D. Moving the contents of ITEM-F to ITEM-B pads the last byte of ITEM-D with a space character.
In contrast, boundary equivalence eliminates this unforeseen result. The elementary items occupy the same relative positions in each group. Therefore, the structures of ITEM-B and ITEM-F are the same, and the results of both group and elementary moves are predictable.
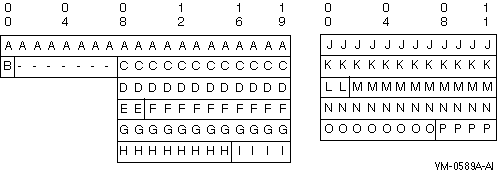
The following series of examples show major-minor storage allocation. The notes after each example indicate its significant features. A hyphen (-) represents fill bytes.
WORKING-STORAGE SECTION.
01 ITEM-A.
03 ITEM-B PIC X.
03 ITEM-C.
05 ITEM-D.
07 ITEM-E PIC 999 COMP SYNC.
07 ITEM-F PIC X(10).
05 ITEM-G REDEFINES ITEM-D.
07 ITEM-H PIC 9(14) COMP SYNC.
07 ITEM-I PIC XXXX.
01 ITEM-J.
03 ITEM-K.
05 ITEM-L PIC 999 COMP SYNC.
05 ITEM-M PIC X(10).
03 ITEM-N REDEFINES ITEM-K.
05 ITEM-O PIC 9(14) COMP SYNC.
05 ITEM-P PIC XXXX.
|
| Previous | Next | Contents | Index |