
Chapter Seven Files
7.1 Chapter Overview
In this chapter you will learn about the file persistent data type. In most assembly languages, file I/O is a major headache. Not so in HLA with the HLA Standard Library. File I/O is no more difficult than writing data to the standard output device or reading data from the standard input device. In this chapter you will learn how to create and manipulate sequential and random-access files.
7.2 File Organization
A file is a collection of data that the system maintains in persistent storage. Persistent means that the storage is non-volatile - that is, the system maintains the data even after the program terminates; indeed, even if you shut off system power. For this reason, plus the fact that different programs can access the data in a file, applications typically use files to maintain data across executions of the application and to share data with other applications.
The operating system typically saves file data on a disk drive or some other form of secondary storage device. As you may recall from the chapter on the memory hierarchy (see "The Memory Hierarchy" on page 303), secondary storage (disk drives) is much slower than main memory. Therefore, you generally do not store data that a program commonly accesses in files during program execution unless that data is far too large to fit into main memory (e.g., a large database).
Under Linux and Windows, a standard file is simply a stream of bytes that the operating system does not interpret in any way. It is the responsibility of the application to interpret this information, much the same as it is your application's responsibility to interpret data in memory. The stream of bytes in a file could be a sequence of ASCII characters (e.g., a text file) or they could be pixel values that form a 24-bit color photograph.
Files generally take one of two different forms: sequential files or random access files. Sequential files are great for data you read or write all at once; random access files work best for data you read and write in pieces (or rewrite, as the case may be). For example, a typical text file (like an HLA source file) is usually a sequential file. Usually your text editor will read or write the entire file at once. Similarly, the HLA compiler will read the data from the file in a sequential fashion without skipping around in the file. A database file, on the other hand, requires random access since the application can read data from anywhere in the file in response to a query.
7.2.1 Files as Lists of Records
A good view of a file is as a list of records. That is, the file is broken down into a sequential string of records that share a common structure. A list is simply an open-ended single dimensional array of items, so we can view a file as an array of records. As such, we can index into the file and select record number zero, record number one, record number two, etc. Using common file access operations, it is quite possible to skip around to different records in a file. Under Windows and Linux, the principle difference between a sequential file and a random access file is the organization of the records and how easy it is to locate a specific record within the file. In this section we'll take a look at the issues that differentiate these two types of files.
The easiest file organization to understand is the random access file. A random access file is a list of records whose lengths are all identical (i.e., random access files require fixed length records). If the record length is n bytes, then the first record appears at byte offset zero in the file, the second record appears at byte offset n in the file, the third record appears at byte offset n*2 in the file, etc. This organization is virtually identical to that of an array of records in main memory; you use the same computation to locate an "element" of this list in the file as you would use to locate an element of an array in memory; the only difference is that a file doesn't have a "base address" in memory, you simply compute the zero-based offset of the record in the file. This calculation is quite simple, and using some file I/O functions you will learn about a little later, you can quickly locate and manipulate any record in a random access file.
Sequential files also consist of a list of records. However, these records do not all have to be the same length1. If a sequential file does not use fixed length records then we say that the file uses variable-length records. If a sequential file uses variable-length records, then the file must contain some kind of marker or other mechanism to separate the records in the file. Typical sequential files use one of two mechanisms: a length prefix or some special terminating value. These two schemes should sound quite familiar to those who have read the chapter on strings. Character strings use a similar scheme to determine the bounds of a string in memory.
A text file is the best example of a sequential file that uses variable-length records. Text files use a special marker at the end of each record to delineate the records. In a text file, a record corresponds to a single line of text. Under Windows, the carriage return/line feed character sequence marks the end of each record. Other operating systems may use a different sequence; e.g., Linux uses a single line feed character while the Mac OS uses a single carriage return. Since we're working with Windows or Linux here, we'll adopt the carriage return/line feed or single line feed convention.
Accessing records in a file containing variable-length records is problematic. Unless you have an array of offsets to each record in a variable-length file, the only practical way to locate record n in a file is to read the first n-1 records. This is why variable-length files are sequential-access - you have the read the file sequentially from the start in order to locate a specific record in the file. This will be much slower than accessing the file in a random access fashion. Generally, you would not use a variable-length record organization for files you need to access in a random fashion.
At first blush it would seem that fixed-length random access files offer all the advantages here. After all, you can access records in a file with fixed-length records much more rapidly than files using the variable-length record organization. However, there is a cost to this: your fixed-length records have to be large enough to hold the largest possible data object you want to store in a record. To store a sequence of lines in a text file, for example, your record sizes would have to be large enough to hold the longest possible input line. This could be quite large (for example, HLA allows lines up to 256 characters). Each record in the file will consume this many bytes even if the record uses substantially less data. For example, an empty line only requires one or two bytes (for the line feed [Linux] or carriage return/line feed [Windows] sequence). If your record size is 256 bytes, then you're wasting 255 or 254 bytes for that blank line in your file. If the average line length is around 60 characters, then each line wastes an average of about 200 characters. This problem, known as internal fragmentation, can waste a tremendous amount of space on your disk, especially as your files get larger or you create lots of files. File organizations that use variable-length records generally don't suffer from this problem.
7.2.2 Binary vs. Text Files
Another important thing to realize about files is that they don't all contain human readable text. Object and executable files are good examples of files that contain binary information rather than text. A text file is a very special kind of variable-length sequential file that uses special end of line markers (carriage returns/line feeds) at the end of each record (line) in the file. Binary files are everything else.
Binary files are often more compact than text files and they are usually more efficient to access. Consider a text file that contains the following set of two-byte integer values:
1234 543 3645 32000 1 87 0As a text file, this file consumes at least 34 bytes (assuming a two-byte end of line marker on each line). However, were we to store the data in a fixed-record length binary file, with two bytes per integer value, this file would only consume 14 bytes - less than half the space. Furthermore, since the file now uses fixed-length records (two bytes per record) we can efficiently access it in a random fashion. Finally, there is one additional, though hidden, efficiency aspect to the binary format: when a program reads and writes binary data it doesn't have to convert between the binary and string formats. This is an expensive process (with respect to computer time). If a human being isn't going to read this file with a separate program (like a text editor) then converting to and from text format on every I/O operation is a wasted effort.
Consider the following HLA record type:
type person: record name:string; age:int16; ssn:char[11]; salary:real64; endrecord;If we were to write this record as text to a text file, a typical record would take the following form (<nl> indicates the end of line marker, a line feed or carriage return/line feed pair):
Hyde, Randall<nl> 45<nl> 555-55-5555<nl> 123456.78<nl>Presumably, the next person record in the file would begin with the next line of text in the text file.
The binary version of this file (using a fixed length record, reserving 64 bytes for the name string) would look, schematically, like the following:
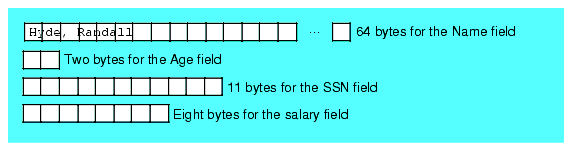
Figure 7.1 Fixed-lengthFormat for Person Record
Don't get the impression that binary files must use fixed length record sizes. We could create a variable-length version of this record by using a zero byte to terminate the string, as follows:

Figure 7.2 Variable-length Format for Person Record
In this particular record format the age field starts at offset 14 in the record (since the name field and the "end of field" marker [the zero byte] consume 14 bytes). If a different name were chosen, then the age field would begin at a different offset in the record. In order to locate the age, ssn, and salary fields of this record, the program would have to scan past the name and find the zero terminating byte. The remaining fields would follow at fixed offsets from the zero terminating byte. As you can see, it's a bit more work to process this variable-length record than the fixed-length record. Once again, this demonstrates the performance difference between random access (fixed-length) and sequential access (variable length, in this case) files.
Although binary files are often more compact and more efficient to access, they do have their drawbacks. In particular, only applications that are aware of the binary file's record format can easily access the file. If you're handed an arbitrary binary file and asked to decipher its contents, this could be very difficult. Text files, on the other hand, can be read by just about any text editor or filter program out there. Hence, your data files will be more interchangeable with other programs if you use text files. Furthermore, it is easier to debug the output of your programs if they produce text files since you can load a text file into the same editor you use to edit your source files.
1There is nothing preventing a sequential file from using fixed length records. However, they don't require fixed length records.
|